A simple tutorial on epidemiology
Much of the science of EMFs revolves round a type of research called epidemiology. We give here a very short and simple introduction to epidemiology and some of the terminology.
What is epidemiology?
Epidemiology is about observing actual human populations and looking for patterns – is exposure A associated with disease B? Epidemiology observes and quantifies these statistical associations. It can discover that A is associated with B. It can say how strong the association is. But on its own it can’t say whether A causes B or not.
What do you observe in epidemiology?
If you just make a single observation – you observed that there were thirty people who were all exposed to A and all contracted disease B – that may be suggestive of a link. But on its own it doesn’t mean much, because you don’t know whether thirty people was what you would expect randomly, or more than you would expect, or fewer. So almost all epidemiology involves comparing two different groups – is the rate of disease higher in one group than another group? Is the exposure more common in one group than another? Often the group we compare to is the rest of the population: did the group we are interested in get the disease more often than the population as a whole?
What two groups can we compare to each other?
There are two main types of epidemiological study and they differ in which the two groups are that they compare.
One approach is to look at a group of people who all have the same exposure – they all work in the same industry, or they all live near the same source of exposure. We then look to see whether they get the disease we’re interested in more or less often than the population as a whole:
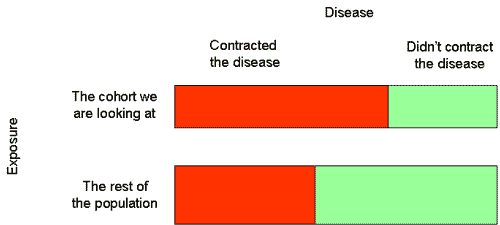
This is called a “cohort study”. And in the above example there is an association - a higher proportion contracted the disease in the group we are investigating than in the rest of the population.
The other approach is to look at people who get a particular disease, and see if they were exposed to the agent we’re interested in more often or less often than the population as a whole:
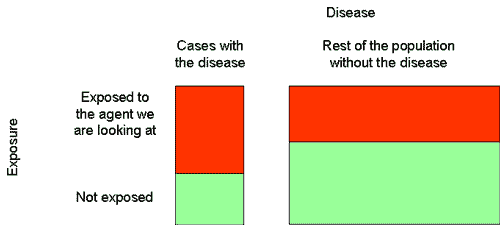
In practice, it’s very difficult to compare them to the whole population, so we usually compare them to a representative sample of the population, called the “control group” or “controls”:
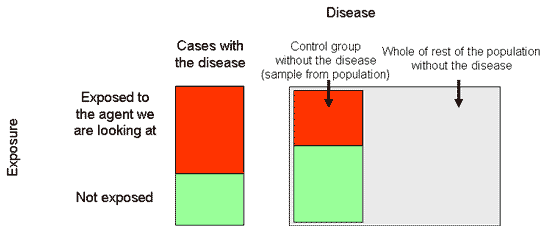
This is called a “case-control study”. In the above example there is an association - a higher proportion of the people who contracted the disease were exposed to the agent than in the control group.
Note: it sounds easy in principle, but selecting the right “control group” from the population – getting a group that is representative without introducing any biases – is one of the big challenges of epidemiology.
How is the result expressed?
Whether we’re doing a cohort study or a case-control study, we are comparing two different groups. We’re interested in the risk in one group compared to the risk in the other group – the population as a whole or the control group. So we express the result as the ratio of the two risks: the “risk ratio” or “relative risk”. A relative risk of one means the risk is the same in both groups (no association), and a relative risk of two, for example, means the risk in the people exposed is twice that in the people not exposed.
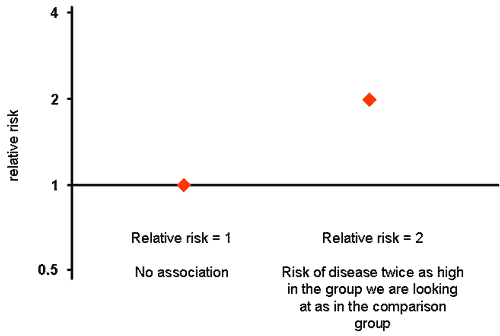
Note: a case-control study, because it doesn’t compare to the whole population but just to a control group, can’t strictly speaking produce a “risk ratio”, it produces an “odds ratio”. But where the disease is a rare one, which is usually true when case-control studies are used, the “odds ratio” and the “risk ratio” are numerically practically the same thing. So in practice, both case-control studies and cohort studies produce relative risks.
How reliable is the result?
We all know that if you toss a coin four times, you might very easily get three heads and one tail rather than the expected two and two. You wouldn’t think the coin was biased just on that result. Toss it forty times, and thirty heads and ten tails is getting less likely. Toss it four hundred times, and if you get three hundred heads and a hundred tails you’d see that as a very strong result and you’d be very suspicious of the coin. But in all three cases the ratio of heads to tails is the same, three-to-one. So as well as knowing the result of a study – the relative risk – we need some measure of how strong the result is – how likely is it that it could have come about just by random chance even if there isn’t actually any underlying association at all.
This is expressed as a “p value”. That is exactly what we said in the previous paragraph – the probability that the result we found (or a more extreme one) could have been produced just by chance if there is no underlying association in the population.
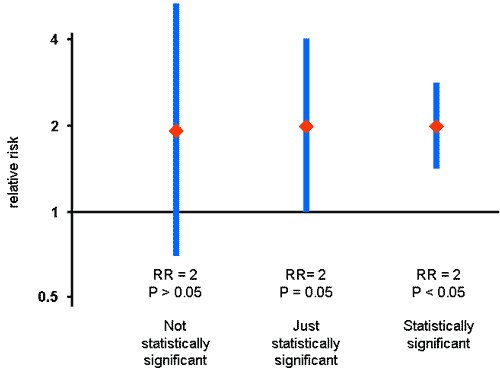
A different way of expressing the same concept is as a “confidence interval”. If we repeated our observation many times, we’d randomly get a slightly different answer every time. The confidence interval is the range of values either side of the relative risk we actually found where, if we repeated our observation many times, we’d find our answer always tended to fall.
Almost every observation we make will find some association or other – to use the same example as previously, you’d virtually never find exactly 200 heads and 200 tails. But common sense that we shouldn’t get excited about 201 heads and 199 tails, whereas we should get excited by 300 and 100. We need a filter to pick out the results that are statistically significant from those that, statistically speaking, are not significant. By long convention, the threshold is taken as a p-value of 5% or 0.05. If the result we found had a 5% or more chance of happening randomly, we don’t regard our finding as significant evidence that there actually is an association. But if the chance of it happening randomly is less than 5%, we do say it is statistically significant.
Expressing the same test in terms of the confidence interval, if the confidence interval – the range of values we might have got randomly – includes one, the no-effect point, then our finding is not statistically significant. But if it doesn’t include one, then our result is statistically significant. If the confidence interval is a “95% confidence interval”, then that is exactly the same test as a p-value of 5%.
Note: what we have just described is a very simple introduction to a very complex area of statistics. Please don’t think this is the whole story! Also, although using p=0.05, or the 95% confidence interval, as the standard test of statistical significance is deeply engrained in epidemiology, it is, at the end of the day, an arbitrary value.
What does it mean if we find an association?
If we find a statistical association between exposure A and disease B – the relative risk was greater than one – it means just that – there is an association. But on its own, it doesn’t mean that A causes B.
- It could be a chance finding. We’d judge that in part by the statistical significance or p-value as we discussed above.
- It could be that our study is biased – there’s actually no association in the population, but one of the groups we studied wasn’t representative of the population, it was biased, and that introduced an association. The commonest form of bias is control bias in a case-control study. See more on bias in EMF studies.
- It could be that it isn’t exposure A that’s causing disease B, it’s some other exposure C. But A and C are associated in the population – the same people are exposed to both – so it looks as if A is linked to B, whereas as really it’s C that is doing the damage. This is called “confounding” and C is a “confounding factor”. See more on confounding factors
Epidemiologists have to make a judgement as to whether they think the association they found is chance, or bias, or confounding, or whether it really is causal. That is a judgement – there is no hard-and-fast rule for deciding, though there are sets of principles to guide that judgement, such as the “Bradford Hill Criteria”. Nearly always, the judgement doesn’t just hang on the epidemiology, but also involves assessing laboratory evidence from biology and whether the link is physically plausible or not.
See more on how epidemiologists decide on causation.
Some other epidemiological terms
The process of assessing the statistical significance of a finding is sometimes called “hypothesis testing”, and asking the question “would I have got this result if there isn’t actually any effect” is called testing the “null hypothesis”.
The two main types of study, as we have described, are cohort studies and case-control studies. But there are others as well. There is a hybrid version called a “nested case-control study”. If you look at one group of people, and don’t look at the individuals, but compare overall exposures and disease rates in that group across time, or compare overall rates in one place to another, that is an “ecological” study. And if you start with an observation of a surprising number of cases all rather close to each other, that is a “cluster”. See more on clusters.
See also:
And more on epidemiology: